こんにちは、kfskyです。
今回は、コンペなどの初手で使用されているLightGBMについて、復習を行っていこうと思います。
僕自身、「こんな感じなのかな?」と思いながら使っている点が多いので、そこら辺の整理などもできればなと思って書いてきます。
LightGBMとは
LightGBMは、決定木アルゴリズムに基づいた勾配ブースティング(Gradient Boosting)の機械学習フレームワークで、米マイクロソフト社から2016年にリリースされました。勾配ブースティングとは複数の弱学習器(LightGBMの場合は決定木)を一つにまとめるアンサンブル学習の「ブースティング」を用いた手法です。
逐次的に弱学習器を構築し、新しい弱学習器を構築する際に,それまでに構築されたすべての弱学習器の結果を利用します。そのためすべての弱学習器が独立に学習されるバギングと比べると、計算を並列化できず学習に時間がかかります。
LightGBMは大規模なデータセットに対して計算コストを極力抑える工夫がされており、その中でも勾配ブースティングで使われる決定木の扱い方に工夫がされています。勾配ブースティングの訓練過程では、決定木の扱い方には「Level-Wise」と「Leaf-Wise」の2つの手法が存在していて、LightGBMでは、「Leaf-Wise」という手法を使っています。(詳しい内容は、リンク先にあります)
LightGBMの特徴
LightGBMの特徴としては以下のようなものがあり、コンペティションの初手で使用されることが多いです。
【メリット】
- モデル訓練時間が短い
- 大容量のデータに対しても対応できる
- 欠損値をそのまま扱える
- スケーリングが不要
- カテゴリカル変数を指定できる
- 特徴量の重要度が把握できる
- 予測精度が比較的高い
- 不要な特徴量を入れても精度が落ちにくい
【デメリット】
- 過学習しやすい
- パラメーターを初期値のままで行うとあまり精度がでない(こともある)
訓練時間が短いというのは、LightGBMで採用している「Leaf-Wise」という手法によるものです。しかし、その代わりに過学習しやすいというデメリットもあります。特にデータ数が一定より少ない場合には、より顕著に現れる場合があります。過学習を抑えるには、パラメータを調整する・データ数を増やすなどの対策が必要です。
個人的には、
- 欠損値をそのまま扱える
- スケーリングが不要
- 不要な特徴量を入れても精度が落ちにくい
- 特徴量の重要度が把握できる
という部分で使用しやすいと感じています。カテゴリカル変数を指定できるという点は、普段からカテゴリカル変数を数値に変換する処理を行っているので、あまり恩恵を受けたことがないです。
LightGBMの実装
【実装する前の準備】
LightGBMの実装する際に、データの準備が必要な部分があります。基本的にコンペティションに出ている方はおなじみなものですが、初めて使う方だと1.の部分で戸惑うのではないかと思います。
- 学習させるデータをすべて数値データにする(カテゴリカル変数で使用する場合は指定する)
- 学習データと評価データに分割する
それでは、実装の中身を見ていこうと思います。今回は、コンペ振り返りにも書きましたが、衛星データに関するコンペティションプラットフォーム「Solafune」で開催されていた「夜間光データからの土地価格を予測」のデータで行っていこうと思います。データの詳細はリンクから確認できます。

モジュールのインポート
まずは、必要なモジュールをインポートします。LightGBMでは、「Python API (ネイティブのAPI)」と「scikit-learn API(Python APIベースのAPI)」の2種類が存在します。今回は「scikit-learn API(Python APIベースのAPI)」の方で実装していきたいと思います。
# pandas, numpyをインポート
import numpy as np
import pandas as pd
# 可視化モジュールをインポート
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 評価指標(今回のコンペティションでは RMSLE
from sklearn.metrics import mean_squared_log_error
# LightGBMをインポート
import lightgbm as lgb
# 時間計測用のライブラリをインポート
from contextlib import contextmanager
from time import timeデータの読み込み
今回使用するデータを読み込みます。今回のデータはすべて数値データであり、特徴量としては4つであることが確認できます。
# ディレクトリ
input_dir = "../input/"
output_dir = "../output/"
train_df = pd.read_csv(input_dir+"TrainDataSet.csv")
test_df = pd.read_csv(input_dir+"EvaluationData.csv")
submission = pd.read_csv(input_dir+"UploadFileTemplate.csv")
# 学習データの先頭5列を表示
train_df.head()
特徴量作成
特徴量の作成に関しては、こちらに記載していますので、参考にしていただければと思います。
最終的な学習データはこのような状態です。(特徴量としては、325個まで増えました)
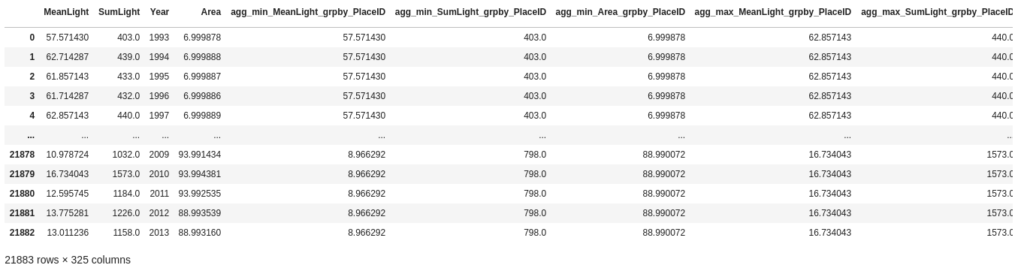
予測モデルの実装
ここから実際に予測モデルを実装していきます。学習データと評価データの分割は交差検証を使用しています。今回はLightGBMでの学習の部分を関数化しています。
まず、学習時間を測定する関数を実装します。
@contextmanager
def timer(logger=None, format_str='{:.3f}[s]', prefix=None, suffix=None):
if prefix: format_str = str(prefix) + format_str
if suffix: format_str = format_str + str(suffix)
start = time()
yield
d = time() - start
out_str = format_str.format(d)
if logger:
logger.info(out_str)
else:
print(out_str)LightGBMでの学習を行う関数を実装して、学習を行います。
def fit_lgbm(X, y, cv, params: dict=None, verbose: int=50):
"""
lightGBM を CrossValidation の枠組みで学習を行なう function
Parameters
----------
X: numpy.ndarray
説明変数
y : Series
目的変数
cv:list
CrossValidationをする際のindex
params:dict
LightGBMのパラメータ
verbose:int
結果の表示タイミング
Returns
-------
oof_pred : numpy.ndarray
OOF予測値
models:list
学習モデル
"""
metric_func = mean_squared_error
if params is None:
params = {}
models = []
# training data の target と同じだけのゼロ配列を用意
# float にしないと悲しい事件が起こるのでそこだけ注意
oof_pred = np.zeros_like(y, dtype=np.float)
for i, (idx_train, idx_valid) in enumerate(cv):
# この部分が交差検証のところです。データセットを cv instance によって分割します
# training data を trian/valid に分割
x_train, y_train = X[idx_train], y[idx_train]
x_valid, y_valid = X[idx_valid], y[idx_valid]
clf = lgb.LGBMRegressor(**params)
with timer(prefix='fit fold={} '.format(i + 1)):
clf.fit(x_train, y_train,
eval_set=[(x_valid, y_valid)],
early_stopping_rounds=verbose,
verbose=verbose)
pred_i = clf.predict(x_valid)
oof_pred[idx_valid] = pred_i
models.append(clf)
print(f'Fold {i} RMSLE: {metric_func(y_valid, pred_i)**.5 :.4f}')
score = metric_func(y, oof_pred)**.5
print('FINISHED | Whole RMSLE: {:.4f}'.format(score))
return oof_pred, models
# LightGBMのパラメータを設定
lgm_params = {
"n_estimators": 10000,
"objective": 'rmse',
"learning_rate": 0.01,
"num_leaves": 31,
"random_state": 2021,
"n_jobs": -1,
"importance_type": "gain",
'colsample_bytree': .5,
"reg_lambda": 5
}
# 学習を実行
# ここでのtrain_x, train_ysは、特徴量生成を行った、説明変数と目的変数です。
# group_cvは交差検証のためのlistを渡します。
oof, models = fit_lgbm(train_x.values, train_ys, group_cv , params=lgm_params)学習を進めると、今回はRMSLEで0.5451という結果でした。それでは特徴量の重要度を見てみましょう。今回、特徴量の説明をしていないので結果を見てもわからないと思いますが、PlaceIDから作成した特徴量が予測モデルの重要度が高いことが確認できます。
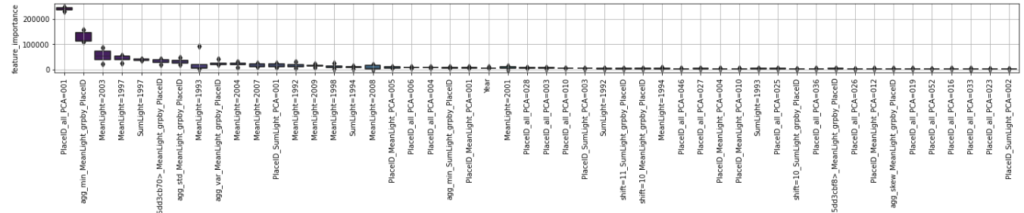
あとはテストデータの予測を行い、結果を提出すれば完了です。前処理の部分を除きましたが、実装までのイメージはつかめたのではないかと思います。
まとめ
自身の復習を含めて、LightGBMについて・実際のコンペティションのデータでの実装例などをまとめました。比較的簡単に実装できるし、一度やり方を覚えるとコンペティションのベースラインは自分で作れるようになってきます。(僕自身、全くできないところから最近は初見のデータでもベースラインモデルの実装まで自力で持っていけるようになってきました)
今回使用したコードはこちらにございます。

参考文献
- u++さん「初手LightGBM」をする7つの理由 https://upura.hatenablog.com/entry/2019/10/29/184617
- 実装コードの参考(僕もこのコンペで様々なことを勉強させていただきました)https://www.guruguru.science/competitions/13/discussions/d8f2d66a-aeee-4789-8b3d-d5935c26b1b7/