こんにちは、kfskyです。
コンペティションなどの振り返りを行ってきましたが、今回は参加しているプログラムでも行っている「データサイエンス100本ノック」を解いていこうと思います。
データサイエンス100本ノックとは?
データサイエンス協会から2020年6月15日にGitHubで公開されたデータサイエンス初学者が構造化データの集計・加工を効率的に学べる学習環境のことをいいます。
使用言語はPython、R、SQLと選択することができ幅広い言語で学習することができます。
100ノックでは、dockerのコンテナから環境を使うことため、dockerをインストールすれば個人で環境を整える必要もなく、簡単に学習できます。
ただ、「そもそもdocker自体が。。。」という方もいらっしゃると思います。そんな方には、Google Colabでの学習を行うこともできます。以下のリンクに方法があります。
(dockerに関しても、今後書いていこうと思います)

各問題でのポイント
各問題での解答はまとまっていますので、ここでは各問題で解答するときに必要な知識や、ポイントをまとめていこうと思います。
問題1~9
・特定の条件のデータを抽出する
特定の条件のデータの抽出には、queryメソッドが有効です。複数条件や比較演算子なども可能ですので、こちらを使用して特定の条件のデータを確認するなどを行うことが可能です。

"""
P-004: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、
顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、
以下の条件を満たすデータを抽出せよ。
顧客ID(customer_id)が"CS018205000001"
"""
df_receipt[["sales_ymd", "customer_id", "product_cd", "amount"]].query("customer_id=='CS018205000001'")
# 以下でも可能
temp = df_receipt[["sales_ymd", "customer_id", "product_cd", "amount"]]
temp[temp['customer_id]=='CS018205000001']問題10~16
・特定の条件のデータを抽出する(文字列メソッド)
文字列が完全一致であれば、in や == などで抽出することができますが、部分的に一致する場合には文字列メソッドを使用することが有効です。
# P-010: 店舗データフレーム(df_store)から、店舗コード(store_cd)が"S14"で始まるものだけ全項目抽出し、10件だけ表示せよ。
df_store.query('store_cd.str.startswith("S14")', engine='python').head(10)
# P-011: 顧客データフレーム(df_customer)から顧客ID(customer_id)の末尾が1のものだけ全項目抽出し、10件だけ表示せよ。
df_customer.query('customer_id.str.endswith("1")', engine='python').head(10)
# P-012: 店舗データフレーム(df_store)から横浜市の店舗だけ全項目表示せよ。
df_store.query('address.str.contains("横浜市")', engine='python')問題17~22
基本メソッドがわかれば問題ないかと思います。設問では、以下のメソッドを使用していきます。
| 要素で並び替え | sort_values() | https://note.nkmk.me/python-pandas-sort-values-sort-index/ |
| 要素の順位づけ | rank() | https://note.nkmk.me/python-pandas-rank/ |
| 件数のカウント | len() | https://note.nkmk.me/python-pandas-len-shape-size/ |
| ユニーク数のカウント | nunique() | https://note.nkmk.me/python-pandas-value-counts/ |
# P-18: 顧客データフレーム(df_customer)を生年月日(birth_day)で若い順にソートし、先頭10件を全項目表示せよ。
df_customer.sort_values("birth_day", ascending=False).head(10)
# P-021: レシート明細データフレーム(df_receipt)に対し、件数をカウントせよ。
len(df_receipt)問題23~35
・Groupbyでデータの集計を行う
いろんな設問がありますが、基本的にgroupbyによる集計について確認するような形です。集計のコーディングは色々書くことができます。
一例を下に載せておきます。

# P-023: レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)と売上数量(quantity)を合計せよ。
df_receipt.groupby("store_cd").sum()[["amount", "quantity"]]
# P-026: レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上日(sales_ymd)と古い売上日を求め、両者が異なるデータを10件表示せよ。
# agg関数を使うことで、同じ要素に対して、複数の集計関数を適用することが可能です。
temp = df_receipt.groupby("customer_id").agg({"sales_ymd":["max", "min"]}).reset_index()
temp.columns = ["_".join(i) for i in temp.columns]
temp[temp.sales_ymd_max != temp.sales_ymd_min].head(10)問題36~40
・DataFrame間の結合
2つのDataFrameに関して、共通のカラムで結合を行う場合、pandas.merge()関数で行うことができます。mergeを行う際は、mergeするkey(どの列で結合するのか?)と結合方法を指定します。結合方法は、以下の4つがあり、自分がほしい結果に合わせて指定する必要があります。

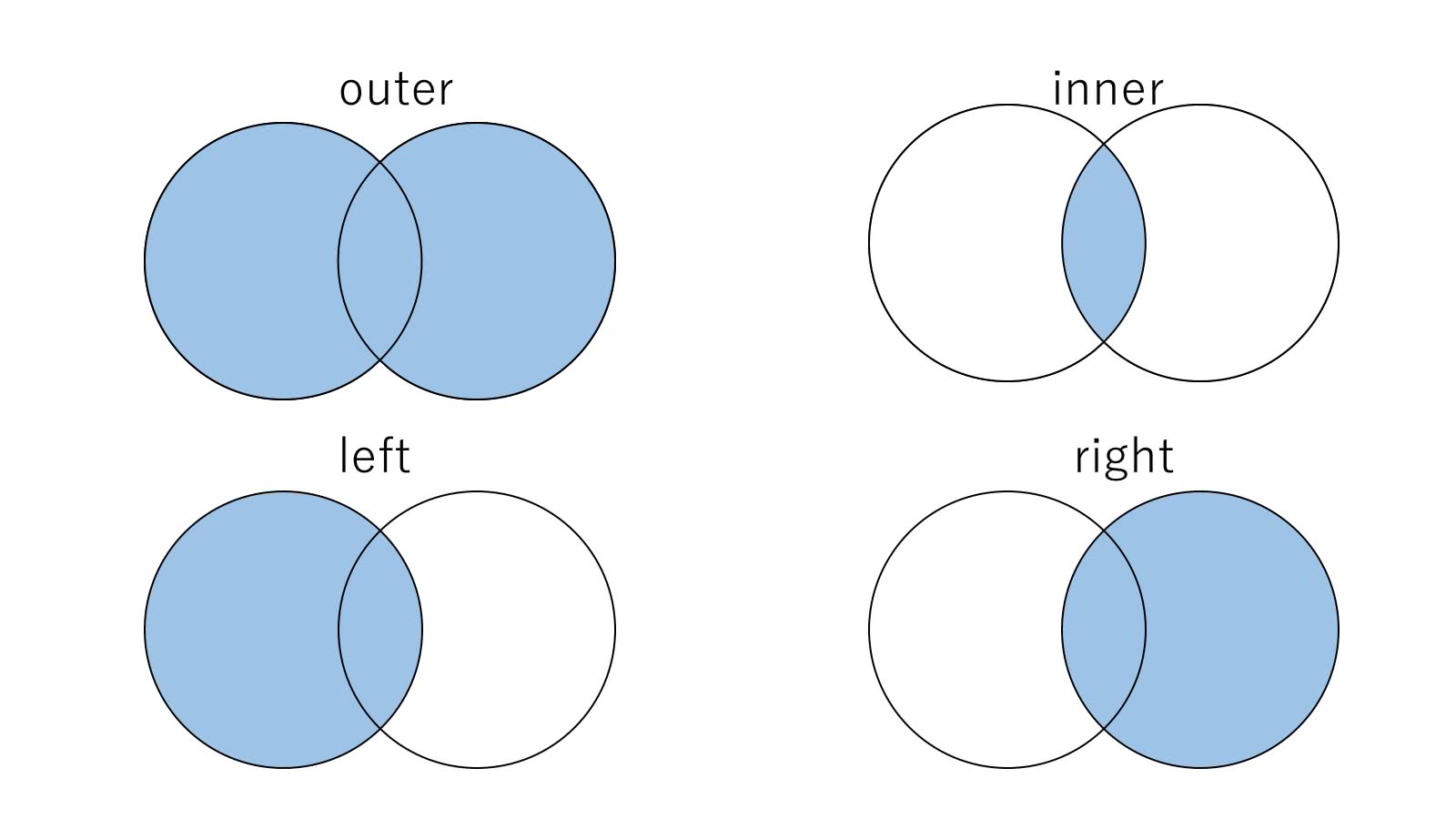
# P-037: 商品データフレーム(df_product)とカテゴリデータフレーム(df_category)を内部結合し、商品データフレームの全項目とカテゴリデータフレームの小区分名(category_small_name)を10件表示させよ。
pd.merge(df_product, df_category[["category_small_cd", "category_small_name"]], on="category_small_cd", how="inner").head(10)
# P-040: 全ての店舗と全ての商品を組み合わせると何件のデータとなるか調査したい。店舗(df_store)と商品(df_product)を直積した件数を計算せよ。
df_store_copy = df_store.copy()
df_product_copy = df_product.copy()
df_store_copy["key"] = "dummy"
df_product_copy["key"] = "dummy"
len(pd.merge(df_product_copy, df_store_copy, on="key", how="outer"))問題41~45
diff関数とpivot_table周りの問題です。この辺は比較的シンプルにできると思います。
# P-042: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、
# 各日付のデータに対し、1日前、2日前、3日前のデータを結合せよ。結果は10件表示すればよい。
temp = df_receipt.groupby("sales_ymd").sum().amount.reset_index()
for i in range(1,4):
temp["amount_diff"+str(i)] = temp.amount.diff(i)
temp.head(10)ひとまずここまで!
各問題の大きな分類ごとにポイントをまとめて来ました。「100本ノックからデータ分析を勉強しよう」と思っても、問題を見ただけでは中々書けないと思います。ポイントがわかると、「こう聞かれていると、この関数使うとできる」というのがわかっているだけでも、自分で解きやすくなると思います。この記事はその一助になればいいかなと思っています。
参考文献
- 【データサイエンスを学ぶあなたへ】100本ノック - 構造化データ処理編 - 最速レビュー動画!【データサイエンティスト協会】#062:https://www.youtube.com/watch?v=fAyj0V2iAc4
- データサイエンス100本ノック解説(P001~020):https://qiita.com/ProgramWataru/items/42ff579a3cdb4f0ad158
- github:https://github.com/The-Japan-DataScientist-Society/100knocks-preprocess