こんにちは、kfskyです。
今回は、前回に引き続き、データサイエンス100本ノックの後半を解いて行こうかと思います。前半に比べて、一筋縄では行かない問題も多いので(1行にまとめることが難しくなっている)、しっかり理解していこうかと思います。
前回までの記事はこちらから。
問題46~51
日付データの取扱についての問題がまとまっています。ここらへんは、to_datetime関数で日付データに変換することで処理を進めることができます。
・問題45
# P-045: 顧客データフレーム(df_customer)の生年月日(birth_day)は日付型(Date)でデータを保有している。
# これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
"""
df_customerのbirth_dayは文字列として格納されています。
なので、to_datetime関数でdatetime型に変換して、所定の文字列の形式に変換します。
今回は、YYYMMDD形式なので、%Y%m%dと指定します。
"""
temp = df_customer.copy()
temp["birth_day"] = pd.to_datetime(temp["birth_day"]).dt.strftime('%Y%m%d')
temp[["customer_id", "birth_day"]].head(10)
・問題49
# P-049: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"年"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。
# データは10件を抽出すれば良い。
"""
年だけを取り出すのは、datetime型のSeriesに対して、Series.dtメソッドで抽出できます。
年だけでなく、月や日、曜日なども抽出することができます。
"""
temp = df_receipt.copy()
temp.sales_epoch = pd.to_datetime(temp.sales_epoch, unit="s")
temp["year"] =temp.sales_epoch.dt.year
temp[["year", "receipt_no", "receipt_sub_no"]].head(10)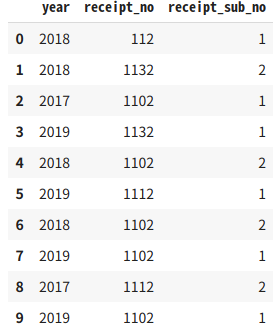
問題52~58
この辺りの問題は、色々な解法があると思います。ただ、僕は以下の流れで書くのが好きなので、そのように書いています。
(1) 関数を実装
(2) 実装した関数をapplyを使って、Seriesに適用させる。
# P-052: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2000円以下を0、2000円超を1に2値化し、顧客ID、売上金額合計とともに10件表示せよ。
# ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
"""
売上金額が2000円超かどうかを判定する関数を実装。
その関数をapplyで適用する形
"""
def test_func(x):
if x >2000:
return 1
else:
return 0
temp = df_receipt.query("not customer_id.str.startswith('Z')", engine='python').groupby("customer_id").sum().amount.reset_index()
temp["amount_over_2000"] = temp["amount"].apply(lambda x: test_func(x))
temp.head(10)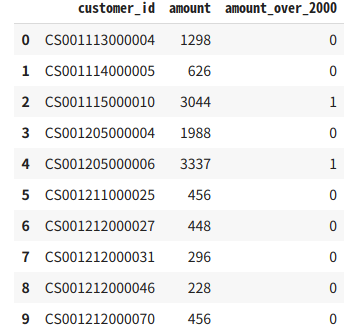
・問題54
文字列の中に特定の文字列が入っていないか?を見つける。なんてのも可能。
# P-054: 顧客データデータフレーム(df_customer)の住所(address)は、埼玉県、千葉県、東京都、神奈川県のいずれかとなっている。
# 都道府県毎にコード値を作成し、顧客ID、住所とともに抽出せよ。値は埼玉県を11、千葉県を12、東京都を13、神奈川県を14とすること。
# 結果は10件表示させれば良い。
def test_func3(x):
if "埼玉県" in x:
return 11
elif "千葉県" in x:
return 12
elif "東京都" in x:
return 13
elif "神奈川県" in x:
return 14
temp = df_customer.copy()
temp["address_flag"] = temp.address.apply(lambda x: test_func3(x))
temp[["customer_id", "address", "address_flag"]].head(10)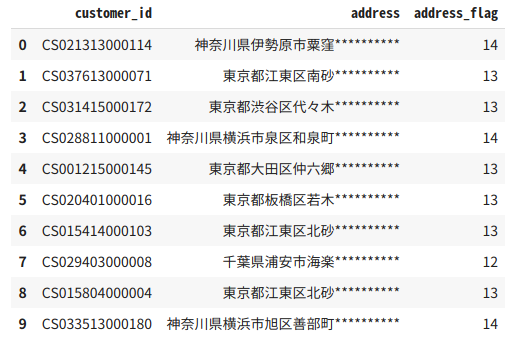
・問題55
"""
P-055: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。
その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額と合計ともに表示せよ。
カテゴリ値は上から順に1〜4とする。結果は10件表示させれば良い。
・最小値以上第一四分位未満
・第一四分位以上第二四分位未満
・第二四分位以上第三四分位未満
・第三四分位以上
"""
#quantile([0, 0.25, 0.5, 0.75, 1.0]).
# 各分位点を求める
p25 = df_receipt.groupby("customer_id").sum().amount.quantile(0.25)
p50 = df_receipt.groupby("customer_id").sum().amount.quantile(0.5)
p75 = df_receipt.groupby("customer_id").sum().amount.quantile(0.75)
def test_func4(x):
if x < p25:
return 1
elif p25<=x<p50:
return 2
elif p50<=x<p75:
return 3
else:
return 4
temp = df_receipt.groupby("customer_id").sum().amount.reset_index()
temp["quantile_flag"] = temp.amount.apply(lambda x: test_func4(x))
temp.head(10)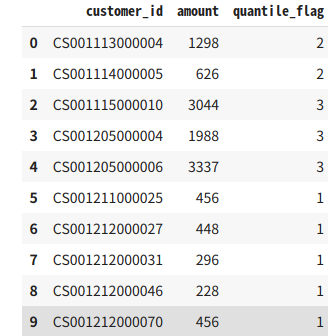
・問題58
自分で関数を作ってもいいですが、pandas には get_dummiesというメソッドがあるので、そちらを使った方が簡単です。
# P-058: 顧客データフレーム(df_customer)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに抽出せよ。結果は10件表示させれば良い。
temp = pd.concat([df_customer["customer_id"], pd.get_dummies(df_customer["gender_cd"])], axis=1)
temp.rename(columns={0:"gender_cd_0", 1:"gender_cd_1", 9:"gender_cd_9"}, inplace=True)
temp.head(10)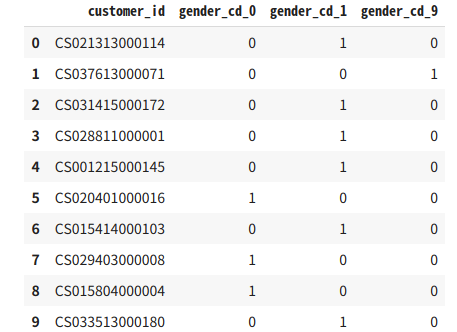
問題59~62
標準化や正規化などの問題があります。実装自体はsklearnをimport しておけば簡単に実装することができます。ただ、何を行っているかを記載しておこうと思います。
標準化とは?
標準化(Standardization)とは、「平均を0に、標準偏差を1にするスケーリング」です。
世間では様々な意味合いで「標準化」という言葉が使われていますが、数学的な定義はこちらになります。データセットx(i)を標準化したデータセットxstd(i)に変換する方法は、平均x¯と標準偏差σxを用いて式(1)で行います。
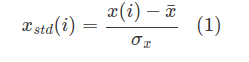
正規化とは?
正規化はデータの種類によって様々な方法がありますが、特に機械学習の分野で使われる正規化には、データの値をある範囲内に収めるスケーリングが頻繁に使われます。数あるスケーリングの中でも、データの最小値xminと最大値xmaxを使って0から1の値に変換する手法をMin-Maxスケーリングと呼びます。
Min-Maxスケーリングで正規化した値xnorm(i)を得るには式(2)を使います。
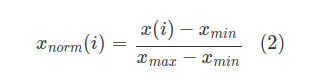
"""
P-059: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を平均0、標準偏差1に標準化して顧客ID、売上金額合計とともに表示せよ。
標準化に使用する標準偏差は、不偏標準偏差と標本標準偏差のどちらでも良いものとする。
ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い
"""
# from sklearn import preprocessing
temp = df_receipt.query('not customer_id.str.startswith("Z")', engine='python').groupby("customer_id").sum().amount.reset_index()
standard_scale = preprocessing.StandardScaler()
temp["Scaled_amount"]=standard_scale.fit_transform(temp[["amount"]])
temp.head(10)"""
P-060: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに表示せよ。
ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
結果は10件表示させれば良い。
"""
# from sklearn import preprocessing
temp = df_receipt.query('not customer_id.str.startswith("Z")', engine='python').groupby("customer_id").sum().amount.reset_index()
min_max_scale = preprocessing.MinMaxScaler()
temp["Scaled_amount"]=min_max_scale.fit_transform(temp[["amount"]])
temp.head(10)問題63~70
消費税の計算などを実際にDataFrameで行うだけです。(休憩ゾーン?)
ただし、値の丸め込みに関しては注意が必要です。端数の処理の例を以下にまとめました。
| 端数の切り捨て | np.floor() |
| 端数の四捨五入 | np.round() |
| 端数の切り上げ | np.ceil |
"""
P-065: 商品データフレーム(df_product)の各商品について、利益率が30%となる新たな単価を求めよ。
ただし、1円未満は切り捨てること。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。
ただし、単価(unit_price)と原価(unit_cost)にはNULLが存在することに注意せよ。
"""
temp = df_product.copy()
temp["new_price"] = temp["unit_cost"]/0.7
# 切り捨て処理
temp["new_price"] = temp["new_price"].apply(lambda x: np.floor(x))
temp["profit_rate"] = (temp["new_price"]-temp["unit_cost"])/temp["new_price"]
temp["profit_rate"].mean(skipna=True)"""
P-066: 商品データフレーム(df_product)の各商品について、利益率が30%となる新たな単価を求めよ。
今回は、1円未満を四捨五入すること(0.5については偶数方向の丸めで良い)。
そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。
ただし、単価(unit_price)と原価(unit_cost)にはNULLが存在することに注意せよ。
"""
temp = df_product.copy()
temp["new_price"] = temp["unit_cost"]/0.7
# 切り捨て処理
temp["new_price"] = temp["new_price"].apply(lambda x: np.round(x))
temp["profit_rate"] = (temp["new_price"]-temp["unit_cost"])/temp["new_price"]
temp["profit_rate"].mean(skipna=True)"""
P-067: 商品データフレーム(df_product)の各商品について、利益率が30%となる新たな単価を求めよ。
今回は、1円未満を切り上げること。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。
ただし、単価(unit_price)と原価(unit_cost)にはNULLが存在することに注意せよ。
"""
temp = df_product.copy()
temp["new_price"] = temp["unit_cost"]/0.7
# 切り捨て処理
temp["new_price"] = temp["new_price"].apply(lambda x: np.ceil(x))
temp["profit_rate"] = (temp["new_price"]-temp["unit_cost"])/temp["new_price"]
temp["profit_rate"].mean(skipna=True)今回はここまで!
今回はここまでにします。前回とは変わって少しコードを書かないと、結果が出てこないものが多くなってきており、少しずつデータ分析に必要な技術を学習している感じが出てくると思います。次回が最後になるかと思います。
![]()